
Place Deduplication. Solution overview
This article observes our solution to Foursquare — Location Matching Kaggle competition. The competition took place from 14th April 2022 to 8th July 2022. Totally 1079 teams took part in the competition, making 22k+ submissions. As a result, our team took 37th place (top 4%), and here we want to present an overview of our solution.
General background and task
The idea of competition is to build a system to de-duplicate data records. The group of points corresponding to one entity is named Point of Interest (POI). The task is having 1M+ records group to independent POIs to find duplicates in a massive set of records.
Each entry includes attributes like the name, street address, coordinates, country, state, and category.
One of the biggest challenges of the competition was dealing with time and resource limits. We had only 9 hours of inference time and a limited Kaggle RAM (12 GB).
Metrics
The primary metric used to evaluate solutions is the mean Intersection over Union (IoU, aka the Jaccard index) of the ground-truth entry matches and the predicted entry matches. The mean is taken sample-wise, meaning that an IoU score is calculated for each row in the submission file, and the final score is their average.
However, we also used Recall for our internal evaluation, which showed the maximum possible IoU at different stages.
Data overview
We were provided a training dataset consisting of 1138812 records labeled 739972 unique POIs, and 221 unique country labels.
We also had missing features for different columns, and their rate differs. For example, we had columns that had almost always some value (latitude, longitude, name, country), and some columns were in >50% records empty(URL, phone, zip)
Also, we had different numbers of records for different countries. That influences metrics a lot as different countries have their specifics, resulting in different metrics scales for each. A number of records for each country have a different influence on the final results.
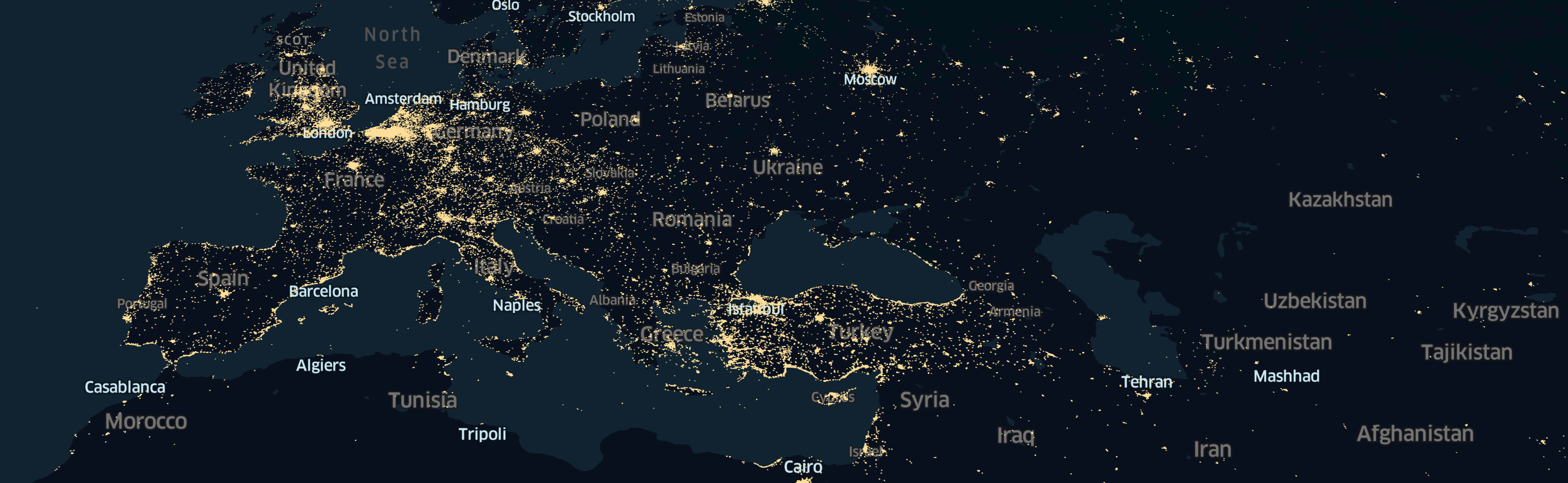
Also, there was a tendency for different places in the world to have different densities of points. That also has a strong influence on the final prediction. For example, we observe big cities have a high density of points, the same works for coastlines, which are excellent places for vacation. Some anomalies were observed, such as India, which is in the top-3 most frequent countries, but all points are concentrated in particular locations. At the same time, Japan, and the UK, for example, have different situations, and points are equally distributed on the whole country’s territory.
The same works also for Ukraine, where the high density of points is shown in big cities Kyiv, Lviv, Odesa, Donetsk, and the beautiful coastline of Ukrainian Crimea.
Solution overview
General solution schema
We have designed our system as a two-stage model. The first level was responsible for collecting the candidates to be a duplicate for each record. The second one was responsible for classifying real duplicates given the set of duplicates. The complete schema is presented in the following picture. During the initial EDA, we found that 99.87% of all pairs are from one country. As a result, we decided to process countries by groups (clusters). So we grouped countries into the following clusters: (TR, GR), (US, CA, MX), (JP), (others).
It allowed us to reduce memory usage and increase processing speed as the indexes became smaller and didn’t significantly change performance.
Level 1
As for the first level (candidates selection), we used several different techniques for candidate selection.
The initial one used only location coordinates (longitude and latitude). We used these features to create a BallTree index with haversine distance for efficient search of location neighbors. We exploited it in two ways: finding the top-30 the closest points to the given one and finding all points in the neighborhood of 200 meters.
The second approach was to find the location neighbors with specific categories. As for this approach, we have trained a W2V model with existing categories. We took all categories for specific POI, collected them to list, and treated each as a token in the sentence. Using such an approach, we could train embeddings of categories to ensure that similar categories correspond to close embeddings. We concatenated them with coordinate values to get the final vector to index. Finally, we used Non-Metric Space Library (NMSLIB) to build an approximate nearest neighbors (ANN) index and efficiently search for duplicate candidates.
The third approach was based on text semantic similarity. We used SentenceTransformers library as a framework to fine-tune custom multilingual models. As a base model, we took paraphrase-multilingual-MiniLM-L12-v2 model as it works with multiple languages, shows good performance, and returns a vector of 384 dimensional, which is twice shorter than regular BERT or other similar models. We built a training dataset from the pairs obtained from the first two approaches. So we had pairs of places and their features. The label was binary, one when two places are from one POI and zero otherwise. We fine-tuned the model for the cosine similarity of the two texts. The text of place was constructed by joining all text features of place with the “[SEP]” token. So, the text for a specific place was constructed with the following pattern: “{name} [SEP] {address} [SEP] {city} [SEP] {url} [SEP] {country} [SEP]“.
We could make embeddings of texts of all places and index them using Non-Metric Space Library (NMSLIB) and cosine similarity distance measurement.
Finally, we also extracted duplicates using complete duplicates by phone number. We considered only numbers that occurred less than ten times to omit hotlines of big chains like McDonalds or IKEA.
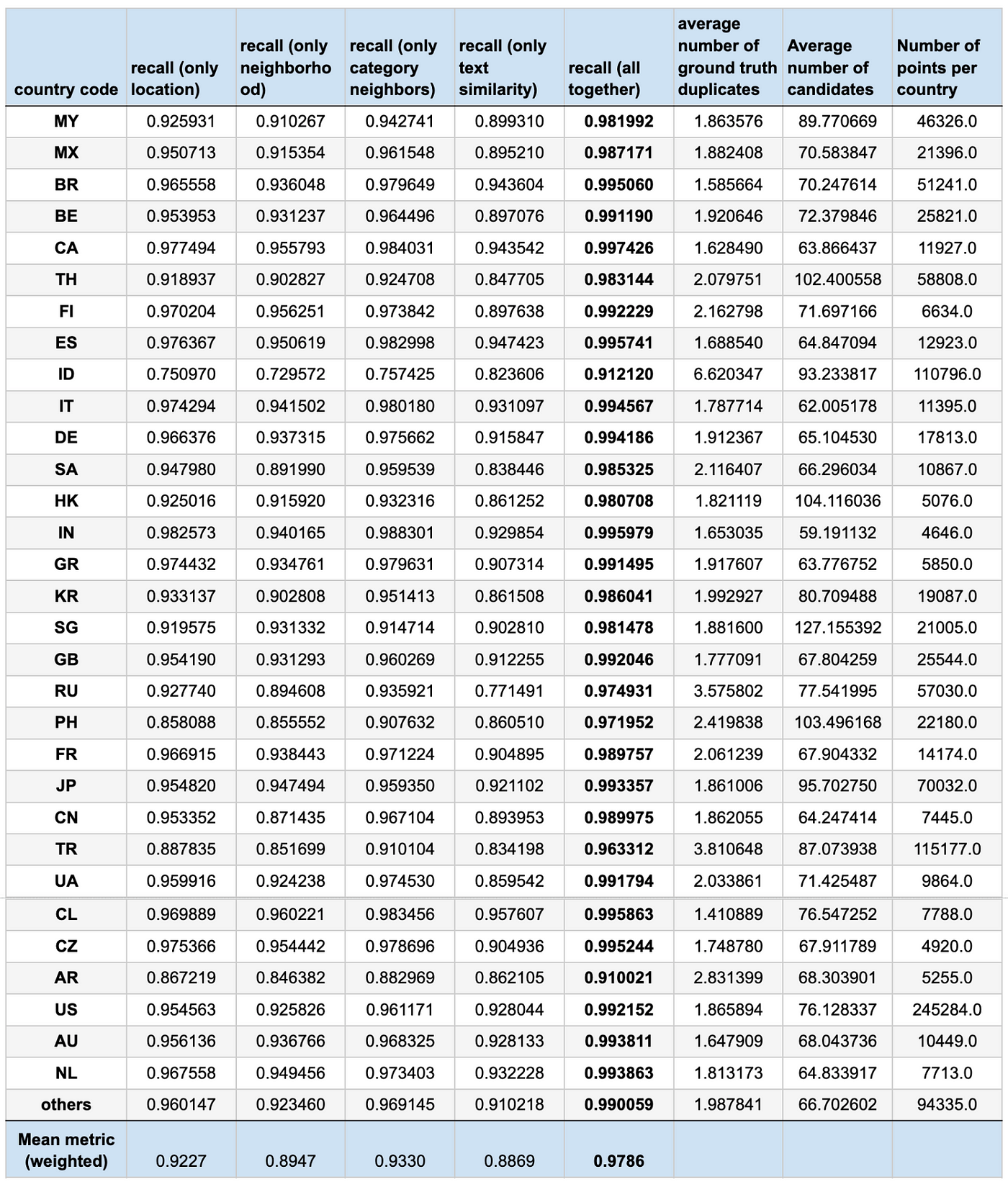
As a result, we achieved a 0.9786 recall for the first stage. We could achieve such a recall only by combining different approaches to candidate selection, which independently had worse results. However, each of them covered their specific cases, which resulted in an excellent boost when combining them. Interesting fact that different countries have their particular characteristics. For example, the average number of ground true candidates varies from 1.41 for CL to 6.62 for ID. The same works for potential duplicates ranging from 59.19 for IN to 127.16 for SG. Taking this into account, we decided to build independent second-stage models for each country presented in the list.
Second level
Having selected candidates, we proceed with building a model to classify if the pair is a duplicate or not. For that, we decided to build an independent CatBoost binary classification model. We used a simple model with default parameters, Log Loss, 25k iterations, and 0.01 learning_rate. Also, we used a 10% test split and best model selection based on metrics on the test. As for a final prediction, we used the standard 0.5 thresholds for final prediction as it showed the best IoU final result in our case.
The most computationally expensive part was feature engineering. We had an average of 81.07 candidates for each point in the dataset. We were processing all points in batches of 500k candidates to avoid going out of RAM limits.
Postprocessing
After the final classification, we collected the pairs that were classified as positive pairs. We used two types of postprocessing:
- 1. If A is a pair of B, then B is a pair of A
- 2. If A is a pair of B and B is a pair of C, then A is a pair of C
In that way, we extended the list of predicted pairs for each point.
Summary
As a result, we achieved the 36th result on the Public leaderboard and 37th on Private out of 1079 teams (top 4%) and got a silver medal, which is quite a remarkable result considering that it was our first serious Kaggle competition.